链研社
用户暂无简介
链研社
DeepSeek 估值 100 亿美金以上,融资 3 亿美金。未上市公司里面与之对比的月之暗面 kimi 最近一轮融资 10 亿美金,估值 180 亿美金。
还有两个已经上市的智谱和 minimax
1. 智谱 AI
上市融资额: 募资净额约 41.7 亿港元,折合约 5.3 亿美金
上市市值: IPO 发行价为 116.2 港元,发行时的整体估值约 518 亿港元。
现在市值: 891 港币,总市值维持在 4000 亿港元左右。
2. MiniMax
上市融资额: IPO 募资额约 48.2 亿港元,折合约 6.16 亿美金
上市市值: IPO 发行价定于上限 165 港元,发行估值超 460 亿港元。
现在市值:859 港币,目前总市值2700 亿港元左右。
还有两个已经上市的智谱和 minimax
1. 智谱 AI
上市融资额: 募资净额约 41.7 亿港元,折合约 5.3 亿美金
上市市值: IPO 发行价为 116.2 港元,发行时的整体估值约 518 亿港元。
现在市值: 891 港币,总市值维持在 4000 亿港元左右。
2. MiniMax
上市融资额: IPO 募资额约 48.2 亿港元,折合约 6.16 亿美金
上市市值: IPO 发行价定于上限 165 港元,发行估值超 460 亿港元。
现在市值:859 港币,目前总市值2700 亿港元左右。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
DeepSeek 即将发布新模型,还在与华为进行深度的底层算力适配所以耽误了不少进度,据说推理和训练将全部跑在华为芯片上。
如果这件事落地,黄仁勋最担心的那个剧本就成真了。
他前几天在 Dwarkesh Patel 的采访里提到:「如果未来某天 DeepSeek 级别的模型率先在华为芯片上发布,那对我们的国家将是一个可怕的结果。」
现在这个「某天」可能就快到了。
黄仁勋反对芯片出口管制的逻辑很简单(当然我觉得他还是想赚中国的钱,这是除美国外最大的市场)
1、中国算力早就够用了。 AI 训练是并行计算问题,一颗 H100 干的活,一堆 7nm 芯片堆起来也能干。中国有大量 7nm 产能和廉价能源,Anthropic 的 Mythos 是在「相当普通的算力规模」上训练出来的,这种算力在中国已经大量存在,说明训练出最顶端的模型,中国的算力已经足够了,华为 2025 年营收 8809 亿元,出货了数以百万计的芯片。
2、算法比算力更决定上限。 中国拥有全球50%以上的 AI 研究者,去看看全球最顶尖的AI实验室就知道了,里面华裔的人数占了多数。DeepSeek 不是靠堆卡堆出来的,是算法层面的突破。算力是下限,算法才是上限。
中国模型的训练成本只有美国的十分之一不到,中国的算力中心电费只有美国的一半,所以现在的中国模型API定价并不是亏本在卖,利润率跟美国相比可能并没我们想象的那么大。那如
如果这件事落地,黄仁勋最担心的那个剧本就成真了。
他前几天在 Dwarkesh Patel 的采访里提到:「如果未来某天 DeepSeek 级别的模型率先在华为芯片上发布,那对我们的国家将是一个可怕的结果。」
现在这个「某天」可能就快到了。
黄仁勋反对芯片出口管制的逻辑很简单(当然我觉得他还是想赚中国的钱,这是除美国外最大的市场)
1、中国算力早就够用了。 AI 训练是并行计算问题,一颗 H100 干的活,一堆 7nm 芯片堆起来也能干。中国有大量 7nm 产能和廉价能源,Anthropic 的 Mythos 是在「相当普通的算力规模」上训练出来的,这种算力在中国已经大量存在,说明训练出最顶端的模型,中国的算力已经足够了,华为 2025 年营收 8809 亿元,出货了数以百万计的芯片。
2、算法比算力更决定上限。 中国拥有全球50%以上的 AI 研究者,去看看全球最顶尖的AI实验室就知道了,里面华裔的人数占了多数。DeepSeek 不是靠堆卡堆出来的,是算法层面的突破。算力是下限,算法才是上限。
中国模型的训练成本只有美国的十分之一不到,中国的算力中心电费只有美国的一半,所以现在的中国模型API定价并不是亏本在卖,利润率跟美国相比可能并没我们想象的那么大。那如
- 赞赏
- 1
- 评论
- 转发
- 分享
SEC 废除「日内交易」门槛,美股散户迎来 25 年来最大规则变化
4 月 14 日,SEC 正式批准 FINRA 提案,废了已经实施25 年的 Pattern Day Trading(PDT)规则。
核心变化三条
1、取消 $25,000 最低账户门槛
2、取消「日内交易者」身份标签
3、用实时风险保证金体系替代原有的交易次数限制
先说旧规则有多离谱
PDT 规则诞生于 2001 年,互联网泡沫破裂 后 SEC 为了保护散户加的限制:5 个交易日内超过 4 次日内交易,账户直接被标记为 PDT,交易权限锁死。
解锁条件?账户里至少放 $25,000
翻译成大白话:没钱就别玩日内交易。这条规则存在了 25 年。25 年里,市场结构、交易技术、参与者构成全变了,规则一个字没动
新规改了什么?
最核心变化不是取消门槛,而是底层 逻辑从「限制行为」变成了「控制风险」
旧逻辑:你做了几次 交易?超过 4 次?锁账户
新逻辑:你当前的风险敞口 是多少?保证金够不够覆盖?不够就不让你开新仓。
具体执行上,FINRA 给券商两条路:
- 实时监控:系统在交易发生前就判断保证金是否充足,不够直接拦截
- 交易日结束计算:每天收盘后算一次日内风险暴露
如果账户返复在 5 个交易日内出现保证金缺口且不补足,会被冻结 90 天的做空和加杠杆权限。小额缺口(低于账户净值 5% 或 $1,000)豁免。
另
4 月 14 日,SEC 正式批准 FINRA 提案,废了已经实施25 年的 Pattern Day Trading(PDT)规则。
核心变化三条
1、取消 $25,000 最低账户门槛
2、取消「日内交易者」身份标签
3、用实时风险保证金体系替代原有的交易次数限制
先说旧规则有多离谱
PDT 规则诞生于 2001 年,互联网泡沫破裂 后 SEC 为了保护散户加的限制:5 个交易日内超过 4 次日内交易,账户直接被标记为 PDT,交易权限锁死。
解锁条件?账户里至少放 $25,000
翻译成大白话:没钱就别玩日内交易。这条规则存在了 25 年。25 年里,市场结构、交易技术、参与者构成全变了,规则一个字没动
新规改了什么?
最核心变化不是取消门槛,而是底层 逻辑从「限制行为」变成了「控制风险」
旧逻辑:你做了几次 交易?超过 4 次?锁账户
新逻辑:你当前的风险敞口 是多少?保证金够不够覆盖?不够就不让你开新仓。
具体执行上,FINRA 给券商两条路:
- 实时监控:系统在交易发生前就判断保证金是否充足,不够直接拦截
- 交易日结束计算:每天收盘后算一次日内风险暴露
如果账户返复在 5 个交易日内出现保证金缺口且不补足,会被冻结 90 天的做空和加杠杆权限。小额缺口(低于账户净值 5% 或 $1,000)豁免。
另
- 赞赏
- 点赞
- 评论
- 转发
- 分享
纳斯达克指数完成了惊人的日线十连涨,美股每次下跌都是机会,只需要干就完了。
之前说在 4 月 15 号之前把美股的仓位建完,一年一度的好时机,和去年的关税战是一模一样
之前说在 4 月 15 号之前把美股的仓位建完,一年一度的好时机,和去年的关税战是一模一样
- 赞赏
- 点赞
- 评论
- 转发
- 分享
Claude 开始反蒸馏和封号的究极手段了,KYC...
中国人天塌了
中国人天塌了

- 赞赏
- 点赞
- 评论
- 转发
- 分享
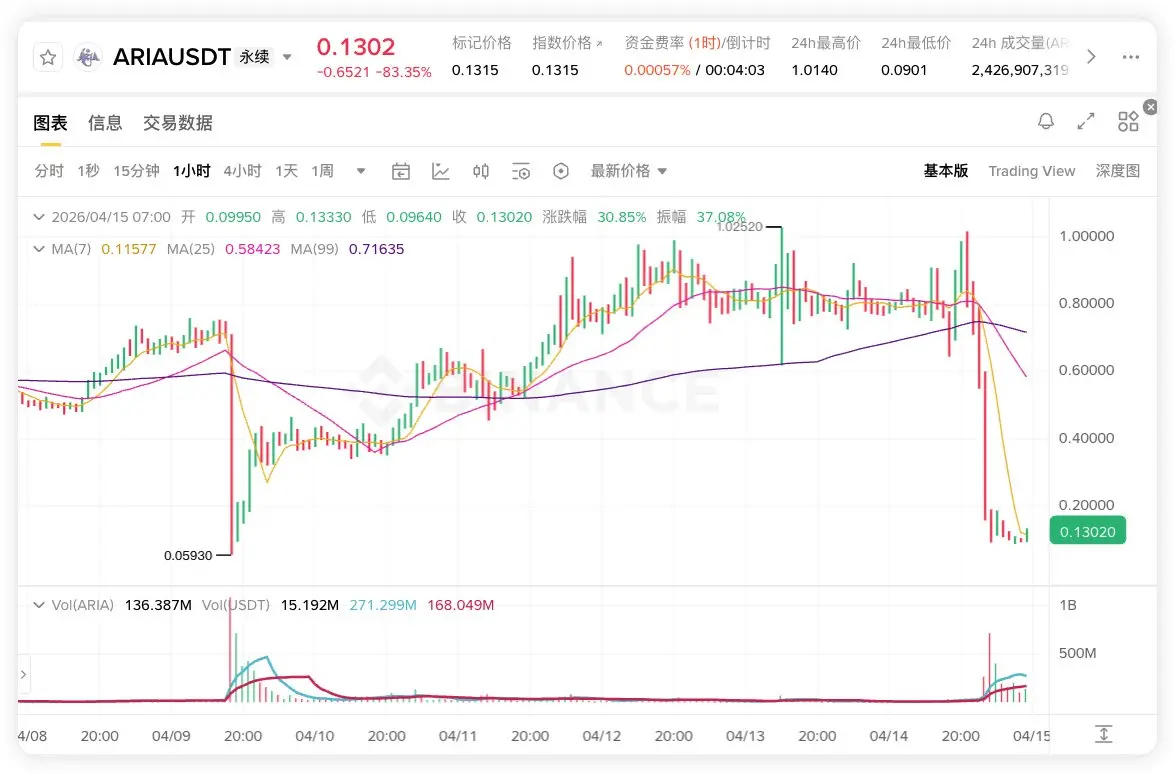
试用了一下Qwen Code 还挺好用的,每天有 1000 次额度,每分钟最多 60 次,没有 Token 上限,基本是够用了,命令行的功能都有中文注释。
Qwen Code 是用 Gemini Code 开源代码的二次开发,现在上面用的是最新的模型 Qwen3.6 plus, coding 模型能力排全球第九弱于 GLM5.1(全球第三),现在的Qwen3.6 plus还只是中等模型的,Qwen3.6 max 的旗舰模型能力应该会超过GLM5.1,正常是在plus一个月左右发布,估计 5 月就能看到,4 月末还有 DeepSeek 的新模型,Qwen 旗舰模型登顶国内第一还是有点难度的
Github 开源仓库:QwenLM/qwen-code
Qwen Code 是用 Gemini Code 开源代码的二次开发,现在上面用的是最新的模型 Qwen3.6 plus, coding 模型能力排全球第九弱于 GLM5.1(全球第三),现在的Qwen3.6 plus还只是中等模型的,Qwen3.6 max 的旗舰模型能力应该会超过GLM5.1,正常是在plus一个月左右发布,估计 5 月就能看到,4 月末还有 DeepSeek 的新模型,Qwen 旗舰模型登顶国内第一还是有点难度的
Github 开源仓库:QwenLM/qwen-code
- 赞赏
- 点赞
- 评论
- 转发
- 分享
试用了一下Qwen Code 还挺好用的,每天有 2000 次额度,每分钟最多 60 次,没有 Token 上限,基本是够用了,命令行的功能都有中文注释。
Qwen Code 是用 Gemini Code 开源代码的二次开发,现在上面用的是最新的模型 Qwen3.6 plus, coding 模型能力排全球第九弱于 GLM5.1(全球第三),现在的Qwen3.6 plus还只是中等模型的,Qwen3.6 max 的旗舰模型能力应该会超过GLM5.1,正常是在plus一个月左右发布,估计 5 月就能看到,4 月末还有 DeepSeek 的新模型,Qwen 旗舰模型登顶国内第一还是有点难度的
Github 开源仓库:QwenLM/qwen-code
Qwen Code 是用 Gemini Code 开源代码的二次开发,现在上面用的是最新的模型 Qwen3.6 plus, coding 模型能力排全球第九弱于 GLM5.1(全球第三),现在的Qwen3.6 plus还只是中等模型的,Qwen3.6 max 的旗舰模型能力应该会超过GLM5.1,正常是在plus一个月左右发布,估计 5 月就能看到,4 月末还有 DeepSeek 的新模型,Qwen 旗舰模型登顶国内第一还是有点难度的
Github 开源仓库:QwenLM/qwen-code
- 赞赏
- 点赞
- 评论
- 转发
- 分享
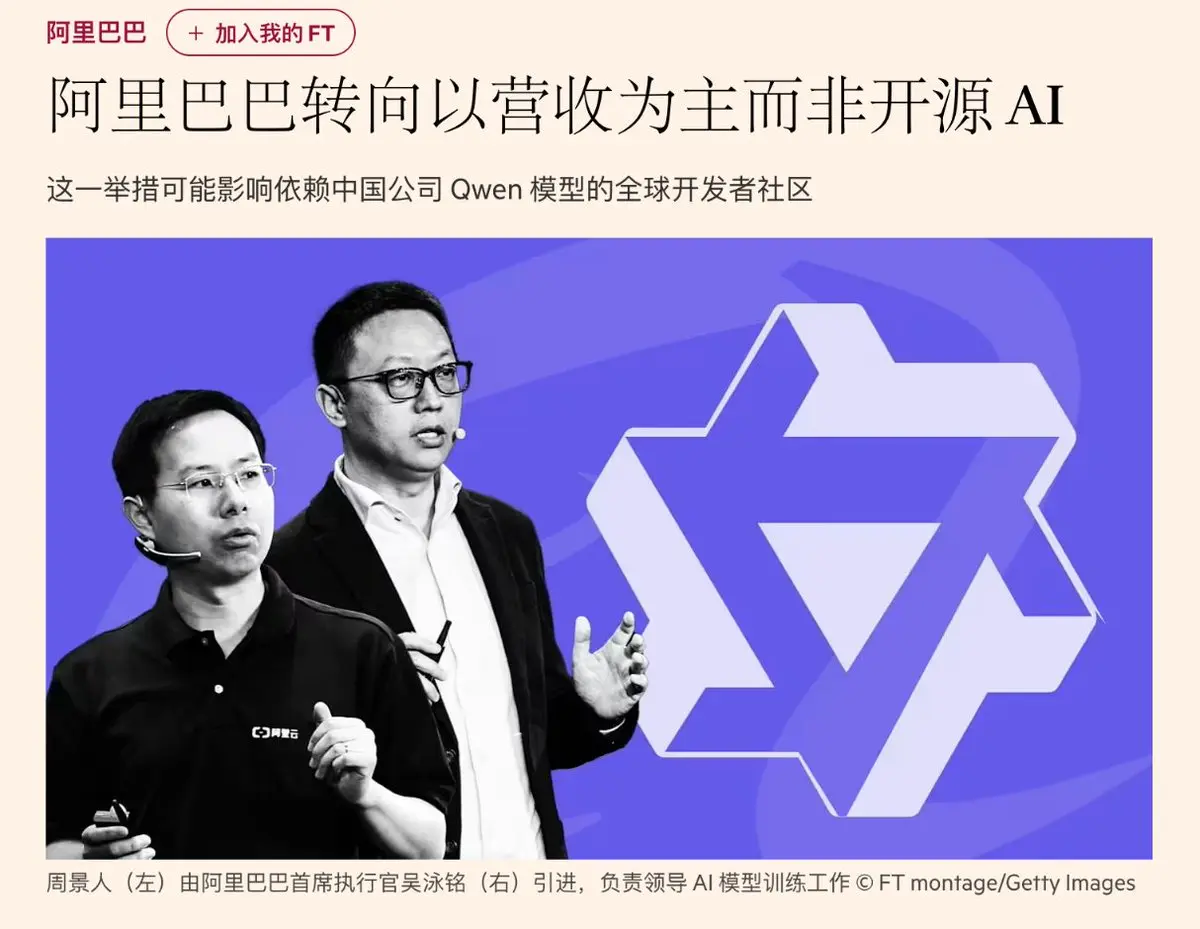
阿里巴巴对 AI 发展进行战略转向,从追求开源生态转向商业变现,Qwen 团队核心人物林俊阳、胡斌元等因战略分歧离职,阿里云前 CTO 周靖人接手,CEO 吴泳铭成立"Alibaba Token Hub"并组建 AI 策略委员会,明确将模型开发与云业务营收目标对齐,公司明确转向,MaaS 和商业化优先。
转型逻辑在当下是非常正确的选择,Qwen 开源虽然获得了全球开发者的口碑,但模型本身并不赚钱。阿里云 AI 收入的大头仍是卖 GPU 算力,MaaS 占比很小且利润薄,有第一梯队的模型能力和大量的 GPU 算力赚的却是微薄的利润,这在商业上是不可持续且失败的。
改革以后,阿里在 AI 上的战略变得和字节在 AI 上的战略高度一致,豆包从一开始就是闭源的,火山引擎一开始就是围绕以 AI 变现为逻辑建设的,Token 的调用量全球第一,把 Token 货币化上走的最前,尽管模型能力不是第一但,但变现率并不比 qwen 差。
转型的代价是,Qwen 开源生态的灵魂人物林俊阳出走,他的离开可能动摇社区信心并引发人才链式流失。更关键的是,MiniMax、智谱等竞争对手在代码生成上已超越 Qwen,模型能力本身在承压。此时转闭源,若产品力不够强,客户只会转向竞品。同时字节跳动的火山引擎增长凶猛,在 token 消费驱动的云销售模式上已抢先布局,毛利比阿里云的卖 GPU 算力高了不知道多少。
所
转型逻辑在当下是非常正确的选择,Qwen 开源虽然获得了全球开发者的口碑,但模型本身并不赚钱。阿里云 AI 收入的大头仍是卖 GPU 算力,MaaS 占比很小且利润薄,有第一梯队的模型能力和大量的 GPU 算力赚的却是微薄的利润,这在商业上是不可持续且失败的。
改革以后,阿里在 AI 上的战略变得和字节在 AI 上的战略高度一致,豆包从一开始就是闭源的,火山引擎一开始就是围绕以 AI 变现为逻辑建设的,Token 的调用量全球第一,把 Token 货币化上走的最前,尽管模型能力不是第一但,但变现率并不比 qwen 差。
转型的代价是,Qwen 开源生态的灵魂人物林俊阳出走,他的离开可能动摇社区信心并引发人才链式流失。更关键的是,MiniMax、智谱等竞争对手在代码生成上已超越 Qwen,模型能力本身在承压。此时转闭源,若产品力不够强,客户只会转向竞品。同时字节跳动的火山引擎增长凶猛,在 token 消费驱动的云销售模式上已抢先布局,毛利比阿里云的卖 GPU 算力高了不知道多少。
所
- 赞赏
- 点赞
- 评论
- 转发
- 分享
比Seedance2.0牛逼的HappyHorse 竟然还开源?
HappyHorse 背后的人是淘天集团的张迪,之前是快手Kling一号位,再之前是阿里妈妈大数据与机器学习工程架构负责人,在阿里待了 10 年, 去年被老东家重新请回去。
不过阿里的公关宣传你懂的,实际用起来可能还要打个折扣,对标Seedance2.0,打平Kling还是可能的,关键是开源啊,那还要啥自行车
HappyHorse 背后的人是淘天集团的张迪,之前是快手Kling一号位,再之前是阿里妈妈大数据与机器学习工程架构负责人,在阿里待了 10 年, 去年被老东家重新请回去。
不过阿里的公关宣传你懂的,实际用起来可能还要打个折扣,对标Seedance2.0,打平Kling还是可能的,关键是开源啊,那还要啥自行车
- 赞赏
- 2
- 评论
- 转发
- 分享
中国大模型的作弊蒸馏之路要被海外御三家联手封杀了,国内大模型的好日子到头了,看看谁会先原形毕露😂
kimi、minimax、DeepSeek 都是上了蒸馏黑名单的,GLM 和 Qwen 倒是没被点名
kimi、minimax、DeepSeek 都是上了蒸馏黑名单的,GLM 和 Qwen 倒是没被点名
- 赞赏
- 点赞
- 评论
- 转发
- 分享
Qwen3.6-Plus 我实测下来是明显强于MiniMax M2.7还是多模态,但是这次没有那么多 AI 博主出彩虹屁评测了,因为阿里把他们断粮了。
大概是阿里因为最近一次财报的问题,把宣传的预算给砍了,要我说这样才对啊,本来就应该凭实力征服,Qwen3.5 出来的时候,搞那么多预算铺垫盖地吹的天花乱坠,结果实测就是一坨屎。
阿里现在的策略转向
- 小模型、小尺寸 Qwen3.5 全开源第一时间开源
- 中等模型 Qwen3.6-Plus 性能超过 MiniMax M2.7 应该会延迟开源,效仿另外三家国产模型
- 旗舰模型 Qwen max 系列,闭源
Qwen3.5-Plus 到 Qwen3.5-Max 大概间隔 1 个月时间,等Qwen3.6-Plus出来之后有可能重登国产模型第一,但是这期间 DeepSeek V4 也要出来了,还有其他国产模型大概也要更新了,目前落后进度 1~2 个月,在各家转向闭源之后Qwen追上是不难,因为国产模型最大的 BUG (蒸馏)已经被 Claude 封堵,蒸馏在开始的时候追进度很快,智能提升非常明显,之后就看各家的硬实力如何了。
大概是阿里因为最近一次财报的问题,把宣传的预算给砍了,要我说这样才对啊,本来就应该凭实力征服,Qwen3.5 出来的时候,搞那么多预算铺垫盖地吹的天花乱坠,结果实测就是一坨屎。
阿里现在的策略转向
- 小模型、小尺寸 Qwen3.5 全开源第一时间开源
- 中等模型 Qwen3.6-Plus 性能超过 MiniMax M2.7 应该会延迟开源,效仿另外三家国产模型
- 旗舰模型 Qwen max 系列,闭源
Qwen3.5-Plus 到 Qwen3.5-Max 大概间隔 1 个月时间,等Qwen3.6-Plus出来之后有可能重登国产模型第一,但是这期间 DeepSeek V4 也要出来了,还有其他国产模型大概也要更新了,目前落后进度 1~2 个月,在各家转向闭源之后Qwen追上是不难,因为国产模型最大的 BUG (蒸馏)已经被 Claude 封堵,蒸馏在开始的时候追进度很快,智能提升非常明显,之后就看各家的硬实力如何了。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
中国的大模型纷纷转向半开源了,最新发布的大模型全都没有立即开源,承诺开源的到现在也还没有开,
说明行业已经走过了用开源换注意力的阶段,进入用闭源换利润的商业化阶段
GLM 5.1 没有第一时间开
MiniMax 2.7 没有开
Qwen 3.6 Plus 也没有开
现在基本转向延迟开源甚至闭源,立即开源等于直接把自己的护城河拆掉。
说明行业已经走过了用开源换注意力的阶段,进入用闭源换利润的商业化阶段
GLM 5.1 没有第一时间开
MiniMax 2.7 没有开
Qwen 3.6 Plus 也没有开
现在基本转向延迟开源甚至闭源,立即开源等于直接把自己的护城河拆掉。
- 赞赏
- 2
- 评论
- 转发
- 分享
做了一个 Deribit 的期权工具,方便做卖出期权抄底,就别玩交易所的双币理财了,自己手搓不好吗?用Deribit 的开放 API 做的,找到适合的卖出期权,筛选出 APR 合适、流动性好。用数据大概判断现在的波动率历史情况是高还是低,什么时候卖权划算,聪明钱方向等
github 仓库 :lianyanshe-ai/deribit-options-monitor
监控了Deribit交易所BTC/ETH期权市场,设计 skill 的思路
1. DVOL波动率分析
- 计算DVOL波动率指数Z-Score值,判断波动率高低区间
- 随行情阈值动态调整,附带信号置信度评估,方便判断
- 历史波动率趋势回溯
2. Sell Put 标的智能推荐
- 扫描全市场期权合约,按到期年化收益率(APR)排序,推荐合适的
- 自动排除流动性差、风险收益比不合理的标的,降低操作风险
3. 大宗交易异动监控
- 监控大额Call/Put订单流向,巨鲸资金布局动向
- 分析市场多空情绪变化
- 可以设定监控预警,异常波动自动触发告警
github 仓库 :lianyanshe-ai/deribit-options-monitor
监控了Deribit交易所BTC/ETH期权市场,设计 skill 的思路
1. DVOL波动率分析
- 计算DVOL波动率指数Z-Score值,判断波动率高低区间
- 随行情阈值动态调整,附带信号置信度评估,方便判断
- 历史波动率趋势回溯
2. Sell Put 标的智能推荐
- 扫描全市场期权合约,按到期年化收益率(APR)排序,推荐合适的
- 自动排除流动性差、风险收益比不合理的标的,降低操作风险
3. 大宗交易异动监控
- 监控大额Call/Put订单流向,巨鲸资金布局动向
- 分析市场多空情绪变化
- 可以设定监控预警,异常波动自动触发告警
- 赞赏
- 点赞
- 评论
- 转发
- 分享
投资里最难赚的钱,不是消息的钱,也不是情绪的钱,是预期差的钱。
所谓预期差,就是你对一家公司的理解,比市场更早、更准。市场还没看见的变化,被你提前看到了;市场还没接受的逻辑,被你提前接受了。等市场慢慢反应过来,股价就开始兑现你的认知。
预期差主要有三种。
第一种是业绩预期差
市场原来只预期公司赚10个亿,你通过调研判断它能赚15个亿。那多出来的5个亿,就是你的优势。但它也最难。你要懂需求、价格、成本、产能、竞争格局,稍有偏差,就会从超预期变成幻想。
第二种是估值预期差
不是简单地觉得公司便宜,是提前看到大多数人还没接受的定价逻辑。比如,一家公司原本被当成普通消费品,但你认为它其实更接近奢侈品,应该给更高估值比如泡泡玛特。一旦市场接受这种逻辑,股价就会重估。问题是,这种预期差很容易讲故事,也很容易被证伪,兑现不了,也是虚妄。
第三种是产业趋势预期差
除了看一家公司,更重要的是看一个行业。你比市场更早判断出某个产业趋势增长,趋势一旦成立,最先涨的往往不是最完美的公司,是最先被看懂的公司。这类投资看起来像投趋势,实质上还是认知差。
但预期差有一个致命弱点:它怕时间。
你对了,市场却迟迟不认;或者你看对了方向,却拿不到兑现的那一刻,逻辑就可能失效。预期差的钱,赚的是你比市场更早。
真正成熟的投资者,往往都经历过一段追逐预期差的岁月。
他们试过寻找市场没看到的东西,试过提前押注变化,试过享受
所谓预期差,就是你对一家公司的理解,比市场更早、更准。市场还没看见的变化,被你提前看到了;市场还没接受的逻辑,被你提前接受了。等市场慢慢反应过来,股价就开始兑现你的认知。
预期差主要有三种。
第一种是业绩预期差
市场原来只预期公司赚10个亿,你通过调研判断它能赚15个亿。那多出来的5个亿,就是你的优势。但它也最难。你要懂需求、价格、成本、产能、竞争格局,稍有偏差,就会从超预期变成幻想。
第二种是估值预期差
不是简单地觉得公司便宜,是提前看到大多数人还没接受的定价逻辑。比如,一家公司原本被当成普通消费品,但你认为它其实更接近奢侈品,应该给更高估值比如泡泡玛特。一旦市场接受这种逻辑,股价就会重估。问题是,这种预期差很容易讲故事,也很容易被证伪,兑现不了,也是虚妄。
第三种是产业趋势预期差
除了看一家公司,更重要的是看一个行业。你比市场更早判断出某个产业趋势增长,趋势一旦成立,最先涨的往往不是最完美的公司,是最先被看懂的公司。这类投资看起来像投趋势,实质上还是认知差。
但预期差有一个致命弱点:它怕时间。
你对了,市场却迟迟不认;或者你看对了方向,却拿不到兑现的那一刻,逻辑就可能失效。预期差的钱,赚的是你比市场更早。
真正成熟的投资者,往往都经历过一段追逐预期差的岁月。
他们试过寻找市场没看到的东西,试过提前押注变化,试过享受
- 赞赏
- 2
- 评论
- 转发
- 分享
OpenAI 说要做一个整合 ChatGPT、编程平台 Codex 以及 成一个统一的桌面端超级应用
然后发现豆包的桌面端更是大乱炖、聊天、浏览器、生图、视频,这些都有了而且早半年以前就是这样了😂
然后发现豆包的桌面端更是大乱炖、聊天、浏览器、生图、视频,这些都有了而且早半年以前就是这样了😂
- 赞赏
- 点赞
- 评论
- 转发
- 分享
特朗普乱搞之后美联储先松口了。
美联储主席鲍威尔:通胀预期似乎已稳定下来。
交易员们取消了对美联储加息的预期,并将今年降息的可能性纳入考量。
美联储主席鲍威尔:通胀预期似乎已稳定下来。
交易员们取消了对美联储加息的预期,并将今年降息的可能性纳入考量。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
小米万亿参数大模型 MiMo-v2pro 继续免费体验一周,教你如何快速上手体验,支持在OpenClaw 免费使用。
现在免费真的很值得试一下,体验下来感觉是国产第一梯队不为过。官方定义为面向 agentic workflow 的旗舰模型:总参数规模超过 1T,支持 1M 上下文,重点强化了复杂流程编排、工程任务推进和真实开发工作流里的可用性。
可以在 OpenClaw、OpenCode、KiloCode、Blackbox 和 Cline里免费体验,推荐用OpenClaw、OpenCode来体验。
一、openclaw 里免费使用
1、注册 openrouter,拿到 API Key
2、openclaw config,model,openrouter
3、搜索 mimo,空格选中openrouter/xiaomi/mimo-v2-pro
4、在对话框输入/model 切换到 mimo-v2-pro 即可
后续如果到期openrouter也可以切换到其他免费模型,推荐stepfun/step-3.5-flash:free,后面有其他厂商在openrouter上免费试用也可以通过同样的方式来操作。
二、OpenCode 里免费使用
尽管小米推荐了很多编程 Agent,但是我觉得最适合的还是 OpenCode,因为支持了终端版、桌面版 Beta,还有各大编程工具的入口。
对新手来说,
现在免费真的很值得试一下,体验下来感觉是国产第一梯队不为过。官方定义为面向 agentic workflow 的旗舰模型:总参数规模超过 1T,支持 1M 上下文,重点强化了复杂流程编排、工程任务推进和真实开发工作流里的可用性。
可以在 OpenClaw、OpenCode、KiloCode、Blackbox 和 Cline里免费体验,推荐用OpenClaw、OpenCode来体验。
一、openclaw 里免费使用
1、注册 openrouter,拿到 API Key
2、openclaw config,model,openrouter
3、搜索 mimo,空格选中openrouter/xiaomi/mimo-v2-pro
4、在对话框输入/model 切换到 mimo-v2-pro 即可
后续如果到期openrouter也可以切换到其他免费模型,推荐stepfun/step-3.5-flash:free,后面有其他厂商在openrouter上免费试用也可以通过同样的方式来操作。
二、OpenCode 里免费使用
尽管小米推荐了很多编程 Agent,但是我觉得最适合的还是 OpenCode,因为支持了终端版、桌面版 Beta,还有各大编程工具的入口。
对新手来说,
- 赞赏
- 点赞
- 评论
- 转发
- 分享
热门话题
查看更多19.12万 热度
66.45万 热度
731.97万 热度
106.58万 热度
45.99万 热度
置顶
📢 Gate 广场|4/17 热议:#山寨币强势反弹
随着 BTC 企稳回升,压抑已久的山寨币市场迎来报复性反弹!
领涨先锋: $ORDI 24H 飙升 190% 领跑赛道。
普涨行情: $SATS、$NEIRO、$AXL 涨幅均超 40%,高波动资产流动性显著回暖。
这究竟是“深坑反弹”的起点,还是主升浪前的最后诱多?你会果断满仓,还是保持空仓观望?
🎁 行情研判,抽 5 位锦鲤瓜分 $1,000 仓位体验券!
💬 本期讨论:
1️⃣ 这波反弹你上车了吗?亮出你的操作策略或收益截图!
2️⃣ 还有哪些币种值得重点关注?
2️⃣ 后续行情如何?留下你的精准预测。
分享您的观点 👉 https://www.gate.com/post
📅 4/17 12:00 - 4/19 18:00 (UTC+8)如何参与 Gate 首期 Pre-IPOs:SpaceX (SPCX) 认购?
🔹 新手也能快速上手,仅需 4 步,轻松搞定认购流程
🔹 认购总量:33,900 $SPCX,认购价:$590
🔹 VIP5+ 用户及超级代理商,可享额外免费空投
📅 认购开启:4月20日18:00 (UTC+8)
前往 Pre-IPOs:https://www.gate.com/ipos/2
更多详情:https://www.gate.com/announcements/article/50724十三载风雨同行,您是 Gate 最珍贵的见证者。分享您的故事,瓜分重磅周年豪礼!
参与方式
1️⃣ 带 #Gate13周年 和相应主题标签,在 13 周年留言板或广场发帖
2️⃣ 分享您与 Gate 的故事、送上祝福,或畅想未来 13 年
13 周年定制礼盒、红牛模型、大额仓位体验券等您来拿!
13周年庆留言板 👉️ https://www.gate.com/activities/13th-anniversary
Gate 广场 👉️ https://www.gate.com/post
13 年成长,感谢有您。您的故事,我们期待聆听!
详情:https://www.gate.com/announcements/article/50694🎉 Gate 广场创作者狂欢正式开启
发文冲榜、社群接龙、分享有奖 — 瓜分 2,000 USDT 及周年礼包
📅 活动时间:4 月 8 日 - 4 月 22 日
✅ 发文冲榜:内容质量 + 互动数据 + 挖矿收益综合评分瓜分1200 USDT
✅ TG群组打卡:每周抽 3 份周年礼盒 + 7 份 200 U 体验金券
✅ X 同步奖:分享内容至 X 平台,瓜分 500 USDT 额外奖池
📌 活动详情:https://www.gate.com/announcements/article/50593
📌 报名链接:https://www.gate.com/questionnaire/7536
#Gate广场 #创作者狂欢 #内容挖矿