DeepSeek released preview versions of DeepSeek-V4-Pro and DeepSeek-V4-Flash on April 24, 2026, both open-weight models with one million token context windows and pricing significantly below comparable Western alternatives. The V4-Pro model costs $1.74 per million input tokens and $3.48 per million output tokens—roughly 1/20th the price of Claude Opus 4.7 and 98% less than GPT-5.5 Pro, according to the company’s official specifications.
Model Architecture and Scale
DeepSeek-V4-Pro features 1.6 trillion total parameters, making it the largest open-source model in the LLM market to date. However, only 49 billion parameters activate per inference pass, using what DeepSeek calls the Mixture-of-Experts approach refined since V3. This design allows the full model to sit dormant while only relevant slices activate for any given request, reducing compute costs while maintaining knowledge capacity.
DeepSeek-V4-Flash operates at a smaller scale with 284 billion total parameters and 13 billion active parameters. According to DeepSeek’s benchmarks, it “achieves comparable reasoning performance to the Pro version when given a larger thinking budget.”
Both models support one million tokens of context as a standard feature—approximately 750,000 words, or roughly the entire “Lord of the Rings” trilogy plus additional text.
Technical Innovation: Attention Mechanisms at Scale
DeepSeek addressed the computational scaling problem inherent in long-context processing by inventing two new attention types, as detailed in the company’s technical paper available on GitHub.
Standard AI attention mechanisms face a brutal scaling problem: every time context length doubles, compute cost roughly quadruples. DeepSeek’s solution involves two complementary approaches:
Compressed Sparse Attention works in two steps. It first compresses groups of tokens—for example, every 4 tokens—into a single entry. Then, instead of attending to all compressed entries, it uses a “Lightning Indexer” to select only the most relevant results for any given query. This reduces the model’s attention scope from a million tokens to a much smaller set of important chunks.
Heavily Compressed Attention takes a more aggressive approach, collapsing every 128 tokens into a single entry without sparse selection. While this loses fine-grained detail, it provides an extremely cheap global view. The two attention types run in alternating layers, allowing the model to maintain both detail and overview.
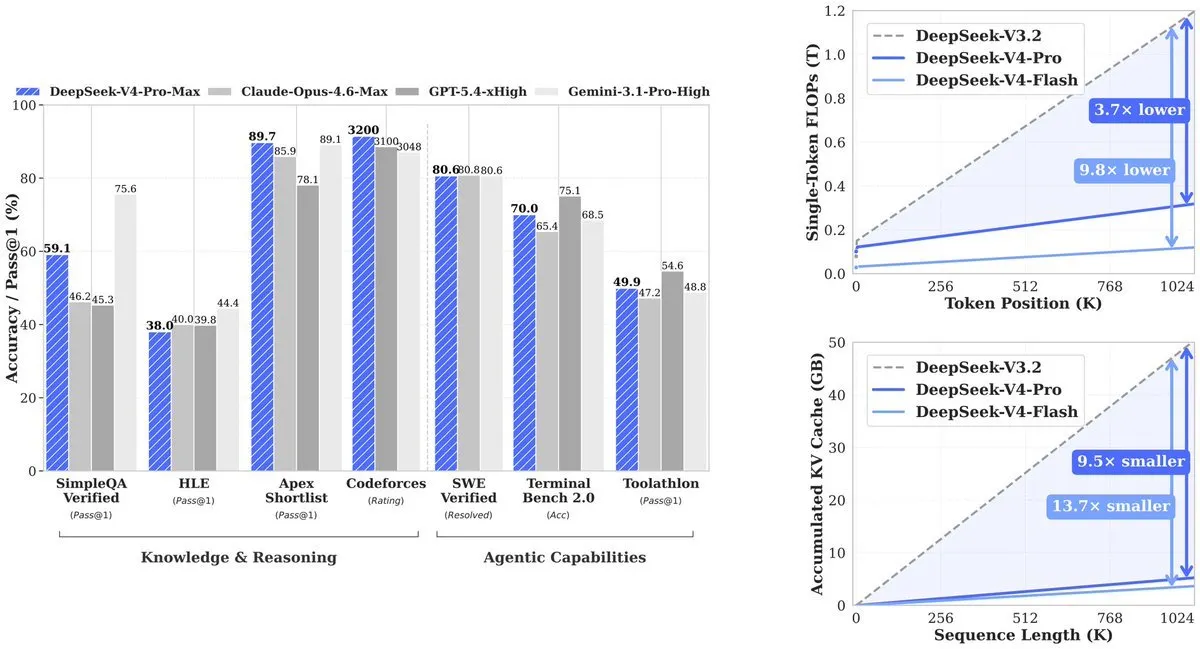
The result: V4-Pro uses 27% of the compute its predecessor (V3.2) required. KV cache—the memory needed to track context—drops to 10% of V3.2. V4-Flash pushes efficiency further: 10% of compute and 7% of memory compared to V3.2.
Benchmark Performance and Competitive Standing
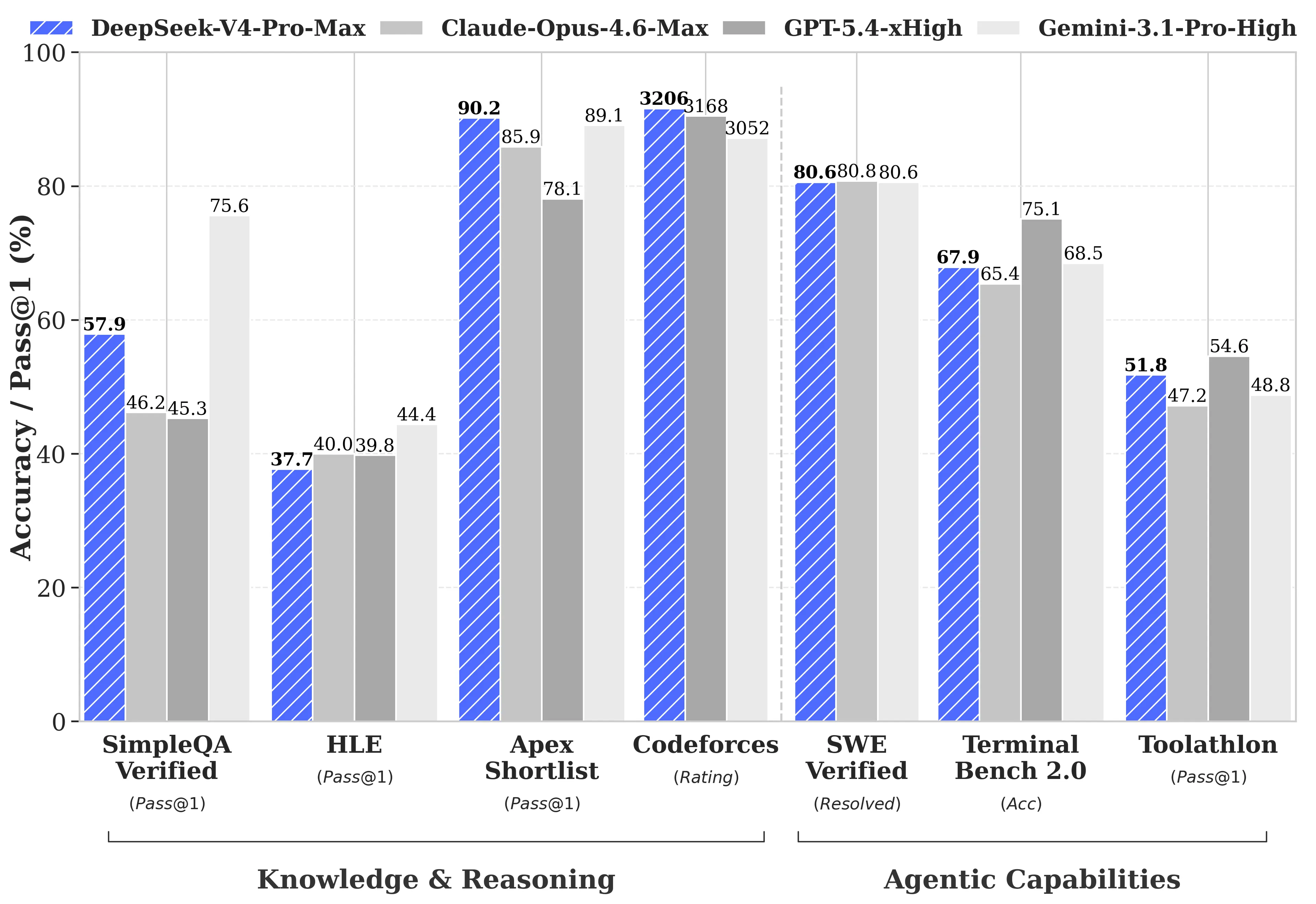
DeepSeek published comprehensive benchmark comparisons against GPT-5.4 and Gemini-3.1-Pro, including areas where V4-Pro trails competitors. On reasoning tasks, V4-Pro’s reasoning lags behind GPT-5.4 and Gemini-3.1-Pro by approximately three to six months, according to DeepSeek’s technical report.
Where V4-Pro leads:
- Codeforces (competitive programming): V4-Pro scored 3,206, placing it around 23rd among actual human contest participants
- Apex Shortlist (curated math and STEM problems): 90.2% pass rate versus Opus 4.6’s 85.9% and GPT-5.4’s 78.1%
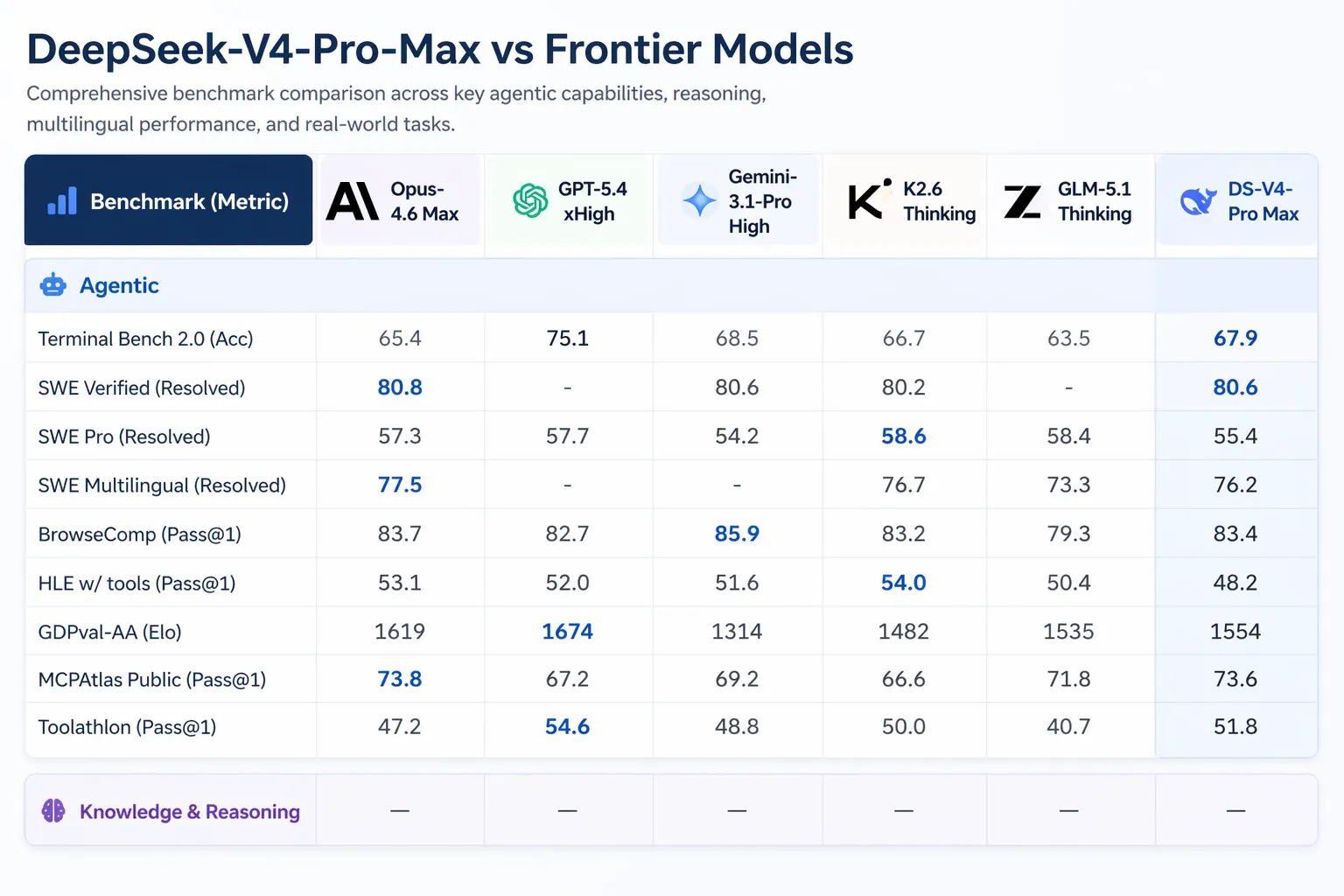
- SWE-Verified (GitHub issue resolution): 80.6%, matching Claude Opus 4.6
Where V4-Pro trails:
- MMLU-Pro (multitasking): Gemini-3.1-Pro at 91.0% versus V4-Pro at 87.5%
- GPQA Diamond (expert knowledge): Gemini at 94.3 versus V4-Pro at 90.1
- Humanity’s Last Exam (graduate-level): Gemini-3.1-Pro at 44.4% versus V4-Pro at 37.7%
On long-context tasks, V4-Pro leads open-source models and beats Gemini-3.1-Pro on CorpusQA (simulating real document analysis at one million tokens) but loses to Claude Opus 4.6 on MRCR, which measures retrieval of specific information buried deep in long text.
Agentic and Coding Capabilities
V4-Pro can run in Claude Code, OpenCode, and other AI coding tools. According to DeepSeek’s internal survey of 85 developers who used V4-Pro as their primary coding agent, 52% said it was ready to be their default model, 39% leaned toward yes, and fewer than 9% said no. DeepSeek’s internal testing indicated V4-Pro outperforms Claude Sonnet and approaches Claude Opus 4.5 on agentic coding tasks.
Artificial Analysis ranked V4-Pro first among all open-weight models on GDPval-AA, a benchmark testing economically valuable knowledge work across finance, legal, and research tasks. V4-Pro-Max scored 1,554 Elo, ahead of GLM-5.1 (1,535) and MiniMax’s M2.7 (1,514). Claude Opus 4.6 scores 1,619 on the same benchmark.
V4 introduces “interleaved thinking,” which retains the full chain of thought across tool calls. In previous models, when an agent made multiple tool calls—such as searching the web, running code, then searching again—the model’s reasoning context was flushed between rounds. V4 maintains reasoning continuity across steps, preventing context loss in complex automated workflows.
Competitive Landscape and Pricing Context
The V4 release arrives amid significant activity in the AI space. Anthropic shipped Claude Opus 4.7 on April 16, 2026. OpenAI’s GPT-5.5 launched on April 23, 2026, with GPT-5.5 Pro priced at $30 per million input tokens and $180 per million output tokens. GPT-5.5 beats V4-Pro on Terminal Bench 2.0 (82.7% versus 70.0%), which tests complex command-line agent workflows.
Xiaomi released MiMo V2.5 Pro on April 22, 2026, offering full multimodal capabilities (image, audio, video) at $1 input and $3 output per million tokens. Tencent released Hy3 on the same day as GPT-5.5.
For pricing perspective: Cline CEO Saoud Rizwan noted that if Uber had used DeepSeek instead of Claude, its 2026 AI budget—reportedly sufficient for four months of usage—would have lasted seven years.
Deployment and Availability
Both V4-Pro and V4-Flash are MIT licensed and available on Hugging Face. The models are text-only for now; DeepSeek stated it is working on multimodal capabilities. Both models can be run for free on local hardware or customized based on company needs.
DeepSeek’s existing deepseek-chat and deepseek-reasoner endpoints already route to V4-Flash in non-thinking and thinking modes respectively. The old deepseek-chat and deepseek-reasoner endpoints will retire on July 24, 2026.
DeepSeek trained V4 partly on Huawei Ascend chips, circumventing U.S. export restrictions. The company stated that once 950 new supernodes come online later in 2026, the Pro model’s already-low price will drop further.
Practical Implications
For enterprises, the pricing structure may shift cost-benefit calculations. A model leading open-source benchmarks at $1.74 per million input tokens makes large-scale document processing, legal review, and code generation pipelines substantially cheaper than six months prior. The one-million-token context allows entire codebases or regulatory filings to be processed in a single request rather than chunked across multiple calls.
For developers and solo builders, V4-Flash is the primary consideration. At $0.14 input and $0.28 output per million tokens, it is cheaper than models considered budget options a year ago while handling most tasks the Pro version manages.