DeepSeek V4-ProはGPT-5.5 Proより98%低コストでローンチします
DeepSeekは2026年4月24日にDeepSeek-V4-ProとDeepSeek-V4-Flashのプレビュー版をリリースしました。どちらもオープンウェイトのモデルで、100万トークンのコンテキストウィンドウを備え、比較対象となる欧米の代替品よりも大幅に低い価格設定です。V4-Proモデルの費用は、入力トークン100万あたり$1.74、出力トークン100万あたり$3.48で、同社の公式仕様によれば、Claude Opus 4.7の約1/20の価格であり、GPT-5.5 Proより98%低いとのことです。
モデルアーキテクチャと規模
DeepSeek-V4-Proは総パラメータ1.6兆を特徴としており、これによりこれまでのLLM市場で最大のオープンソースモデルとなります。しかし、推論の1パスでアクティブになるのはわずか490億パラメータで、DeepSeekがV3以降洗練したと呼ぶMixture-of-Experts(混合エキスパート)アプローチを使用しています。この設計により、モデル全体を眠らせておき、特定のリクエストに関連する部分のみをアクティブ化できます。これにより、計算コストを削減しながら、知識容量を維持します。
DeepSeek-V4-Flashは総パラメータ2840億で、アクティブパラメータは130億です。DeepSeekのベンチマークによれば、「より大きな思考予算が与えられた場合、Pro版と同等の推論性能を達成する」としています。
どちらのモデルも標準機能として100万トークンのコンテキストをサポートします。これはおよそ75万語、または「ロード・オブ・ザ・リング」三部作全体に加えて追加のテキストに相当します。
技術革新:スケールにおける注意機構
DeepSeekは、長いコンテキスト処理に内在する計算スケーリング問題を解決するために、同社の技術論文(GitHubで公開されているもの)で詳述されている2種類の新しい注意(attention)タイプを発明しました。
標準的なAIの注意機構は、残酷なスケーリング問題に直面します。コンテキスト長が2倍になるたびに、計算コストはおおむね4倍になるためです。DeepSeekの解決策は、2つの補完的アプローチです。
**圧縮スパース注意(Compressed Sparse Attention)**は2段階で動作します。まず、トークンのグループ(たとえば4トークンごと)を1つのエントリに圧縮します。次に、すべての圧縮されたエントリに注目するのではなく、「Lightning Indexer」を使って、任意のクエリに対して最も関連性の高い結果だけを選択します。これにより、モデルの注意範囲が100万トークンから、より小さな重要チャンクの集合へと縮小されます。
**大幅圧縮注意(Heavily Compressed Attention)**は、さらに踏み込んだアプローチで、128トークンごとをスパース選択なしで1つのエントリへと畳み込みます。微細な詳細は失われますが、非常に安価なグローバルな見通しが得られます。2種類の注意機構は交互の層で動作し、モデルが詳細と俯瞰の両方を維持できるようにします。
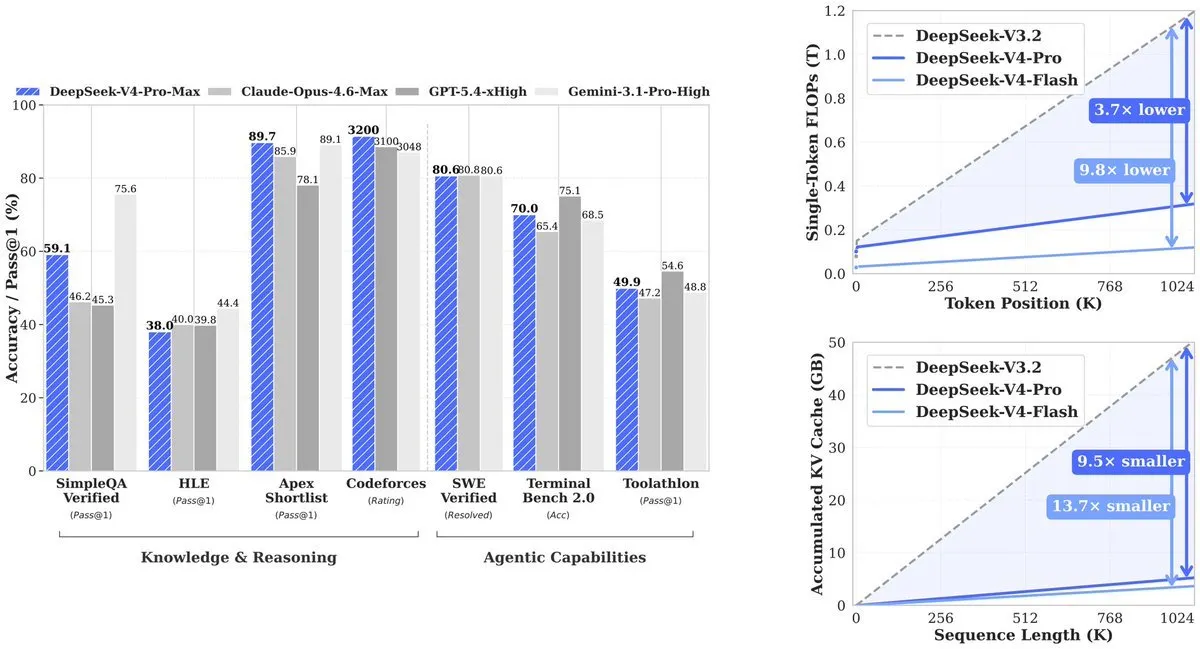
その結果:V4-Proは先行モデル (V3.2) が必要としていた計算の27%を使用します。KVキャッシュ(コンテキスト追跡に必要なメモリ)はV3.2の10%に低下します。V4-Flashはさらに効率を押し進めます:V3.2と比べて計算10%およびメモリ7%です。
ベンチマーク性能と競争上の位置づけ
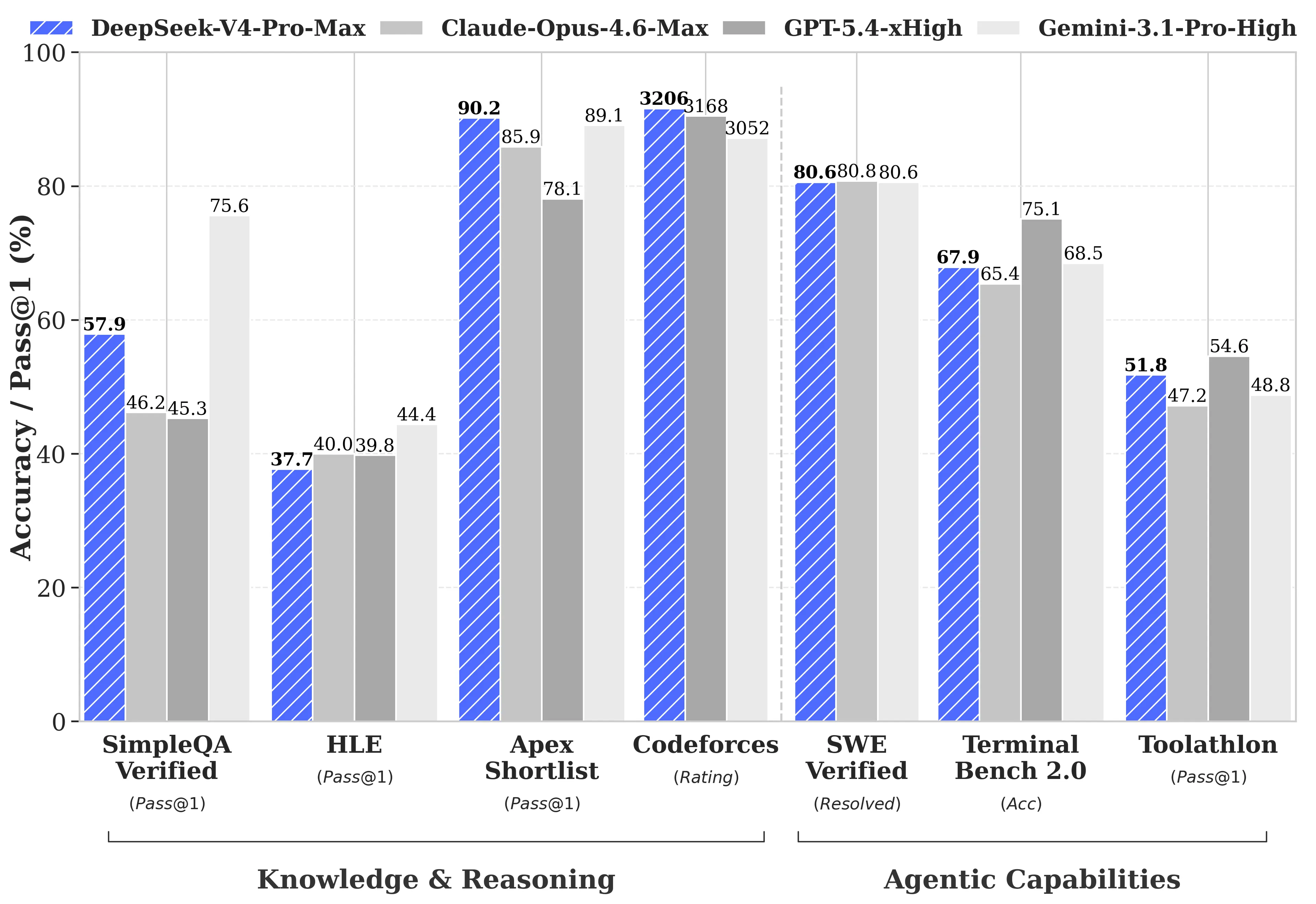
DeepSeekはGPT-5.4およびGemini-3.1-Proに対する包括的なベンチマーク比較を公開し、V4-Proが競合に遅れる領域も含めています。DeepSeekの技術レポートによれば、推論タスクにおいてV4-Proの推論はGPT-5.4およびGemini-3.1-Proに対して約3〜6か月遅れています。
V4-Proが主導する領域:
- Codeforces (競技プログラミング):V4-Proは3,206をスコアし、実際の人間参加者の中で約23位でした
- Apex Shortlist (厳選された数学およびSTEM問題):Opus 4.6の85.9%およびGPT-5.4の78.1%に対して90.2%の合格率
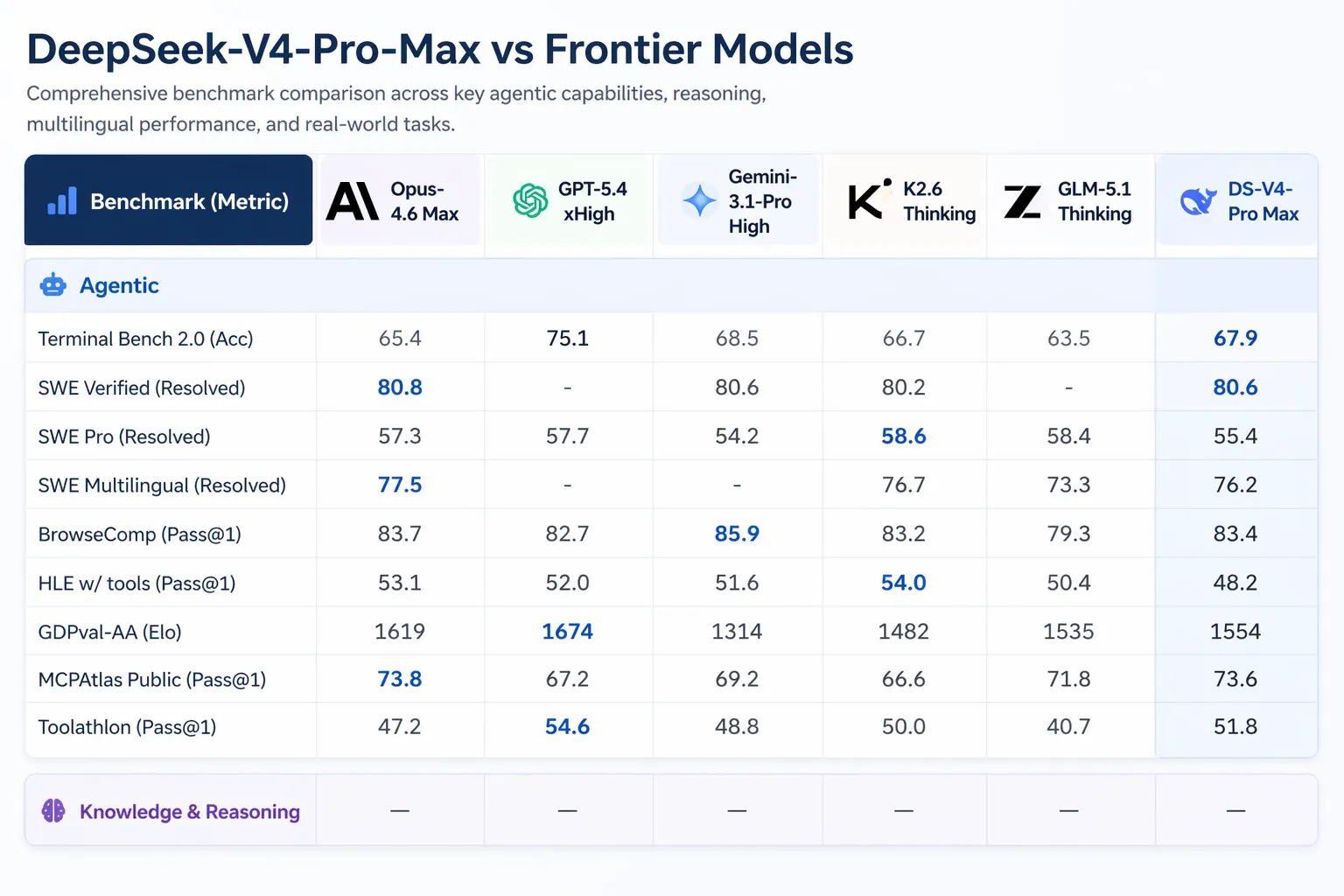
- SWE-Verified (GitHubのissue解決):80.6%で、Claude Opus 4.6と一致
V4-Proが劣後する領域:
- MMLU-Pro (マルチタスキング):Gemini-3.1-Proが91.0%であるのに対し、V4-Proは87.5%
- GPQA Diamond (専門知識):Geminiが94.3であるのに対し、V4-Proは90.1
- Humanity’s Last Exam (大学院レベル):Gemini-3.1-Proが44.4%であるのに対し、V4-Proは37.7%
長いコンテキストのタスクでは、V4-Proはオープンソースモデルで先行し、CorpusQA (100万トークンでの実際のドキュメント分析をシミュレート) ではGemini-3.1-Proを上回りますが、長文の奥深くに埋もれた特定情報の検索を測定するMRCRではClaude Opus 4.6に負けています。
エージェント的およびコーディング機能
V4-ProはClaude Code、OpenCode、その他のAIコーディングツールで動作できます。DeepSeekの、V4-Proを主要なコーディングエージェントとして使用した85人の開発者に対する社内調査によれば、52%が「デフォルトモデルとして準備ができている」と答え、39%が「はい寄り」とし、9%未満が「いいえ」と答えました。DeepSeekの社内テストでは、V4-ProはClaude Sonnetを上回り、エージェント的コーディングタスクでClaude Opus 4.5に近づくことが示されています。
Artificial Analysisは、GDPval-AAにおいて、V4-Proを全てのオープンウェイトモデルの中で1位にランク付けしました。このベンチマークは、金融、法務、研究タスクにまたがる経済的価値のある知識労働をテストします。V4-Pro-Maxは1,554 Eloで、GLM-5.1 (1,535) およびMiniMaxのM2.7 (1,514) より先行しています。同じベンチマークでClaude Opus 4.6は1,619です。
V4は「インターリーブド・シンキング(思考のインタリーブ)」を導入し、ツール呼び出しをまたいで思考の完全なチェーンを保持します。従来のモデルでは、エージェントが複数のツール呼び出しを行ったとき(たとえばウェブ検索、コード実行、そして再度検索など)、ラウンド間でモデルの推論コンテキストがフラッシュされていました。V4はステップ間で推論の継続性を維持し、複雑な自動化されたワークフローでのコンテキスト喪失を防ぎます。
競争環境と価格の文脈
V4のリリースは、AI分野で大きな動きのさなかに到来します。Anthropicは2026年4月16日にClaude Opus 4.7を出荷しました。OpenAIのGPT-5.5は2026年4月23日にローンチされ、GPT-5.5 Proは入力トークン100万あたり $30 と、出力トークン100万あたり $180 の価格設定です。GPT-5.5はTerminal Bench 2.0 ( 82.7% 対 70.0%) でV4-Proを上回っています。これは、複雑なコマンドライン・エージェントのワークフローをテストするものです。
Xiaomiは2026年4月22日にMiMo V2.5 Proをリリースし、完全なマルチモーダル機能 (image, audio, video) を入力あたり $1 および出力あたり $3 (100万トークンあたり)で提供しました。TencentはGPT-5.5と同じ日にHy3をリリースしました。
価格の観点:ClineのCEO Saoud Rizwanは、もしUberがClaudeの代わりにDeepSeekを使っていたなら、(4か月分の利用に十分だと報じられている)同社の2026年のAI予算は7年間持ったはずだと述べました。
デプロイと提供
V4-ProとV4-FlashはいずれもMITライセンスで、Hugging Faceで利用可能です。現時点ではモデルはテキスト専用です。DeepSeekはマルチモーダル機能に取り組んでいると述べています。どちらのモデルもローカル環境で無料で実行でき、また企業のニーズに基づいてカスタマイズすることも可能です。
DeepSeekの既存のdeepseek-chatおよびdeepseek-reasonerエンドポイントは、すでに非思考モードと思考モードそれぞれでV4-Flashにルーティングしています。古いdeepseek-chatおよびdeepseek-reasonerエンドポイントは2026年7月24日に廃止されます。
DeepSeekはV4を部分的にHuaweiのAscendチップで学習しており、米国の輸出規制を回避しました。同社は、2026年後半に950の新しいスーパーノードが稼働すると、Proモデルのすでに低い価格がさらに下がると述べました。
実務上の含意
企業にとっては、価格構造が費用対効果の計算を変える可能性があります。入力トークン100万あたり$1.74という価格でオープンソースのベンチマークをリードするモデルは、大規模なドキュメント処理、法務レビュー、コード生成パイプラインを、6か月前と比べて大幅に安くします。100万トークンのコンテキストにより、コードベース全体や規制関連の提出書類を、複数回の呼び出しに分割するのではなく、1つのリクエストで処理できます。
開発者や個人のビルダーにとっては、V4-Flashが主要な検討対象です。入力が100万トークンあたり$0.14、出力が100万トークンあたり$0.28で、1年前に「予算オプション」として検討されていたモデルよりも安価でありつつ、Pro版が扱うほとんどのタスクをこなします。