À mesure que les applications d’IA et les Agents IA progressent rapidement, de plus en plus de systèmes adoptent des architectures multi-modèles. Chaque modèle d’IA possède des atouts spécifiques en matière de raisonnement, de rapidité de réponse et de structure de coûts. S’appuyer sur un seul modèle pour toutes les tâches entraîne souvent des coûts élevés ou un manque d’efficacité. Ainsi, le routage de modèles d’IA s’impose comme un élément essentiel de l’infrastructure IA moderne.
Les AI Routers permettent de répartir intelligemment les tâches entre plusieurs modèles, renforçant la flexibilité, l’évolutivité et la stabilité des systèmes d’IA. Cette approche collaborative et multi-modèles constitue désormais le socle des plateformes AI SaaS, des Agents IA et des applications automatisées.
Qu’est-ce que le routage de modèles d’IA ?
Le routage de modèles d’IA est un mécanisme technologique qui gère l’orientation des requêtes entre plusieurs modèles d’IA. Son but principal est de sélectionner le modèle le mieux adapté à chaque requête, selon les besoins spécifiques de la tâche.
Traditionnellement, une application d’IA s’appuie sur un seul modèle. Par exemple, un chatbot peut uniquement appeler l’API d’un grand modèle de langage spécifique. Or, les tâches présentent des exigences variées :
- La synthèse de texte ou les questions-réponses simples nécessitent rarement un raisonnement avancé
- L’analyse logique complexe ou la génération de code requièrent des modèles plus puissants
- La traduction multilingue peut bénéficier de modèles spécialisés et optimisés
Recourir à un modèle hautes performances pour chaque tâche augmente les coûts du système. À l’inverse, confier des tâches complexes à des modèles basiques nuit à la qualité.
Le routage de modèles d’IA analyse chaque requête et l’oriente dynamiquement vers le modèle le plus pertinent, en équilibrant performance et coût.
Pourquoi les applications d’IA nécessitent-elles plusieurs modèles ?
Avec l’évolution de l’IA, les modèles deviennent de plus en plus spécialisés selon leurs capacités et leurs cas d’usage. Les architectures multi-modèles s’imposent ainsi comme la norme pour les applications modernes.
D’abord, chaque modèle a ses atouts. Certains excellent dans le raisonnement complexe, d’autres sont optimisés pour la rapidité ou le coût. En combinant plusieurs modèles, les systèmes associent le modèle le plus adapté à chaque tâche.
Ensuite, les architectures multi-modèles réduisent les coûts d’exploitation. Les tâches simples sont traitées par des modèles économiques, tandis que les tâches complexes sont confiées à des modèles performants, ce qui réduit significativement les coûts globaux.
Enfin, cette approche améliore la stabilité du système. Si un modèle rencontre une défaillance ou devient indisponible, les requêtes sont redirigées vers d’autres modèles, assurant ainsi la continuité du service.
Les systèmes de routage de modèles d’IA reposent généralement sur un moteur de routage pour déterminer quel modèle traite chaque requête. Ce moteur prend en compte plusieurs paramètres :
Complexité de la tâche : Analyse les détails de la requête — longueur du prompt, type de tâche — pour décider si un modèle avancé est requis.
Capacités des modèles : Certains modèles sont plus adaptés à des tâches spécifiques, telles que la génération de code ou le traitement multimodal.
Vitesse de réponse : Pour les applications temps réel (chatbots, Agents IA), une faible latence est essentielle.
Coût d’invocation : Les différences de prix entre les API des modèles influencent les choix de routage.
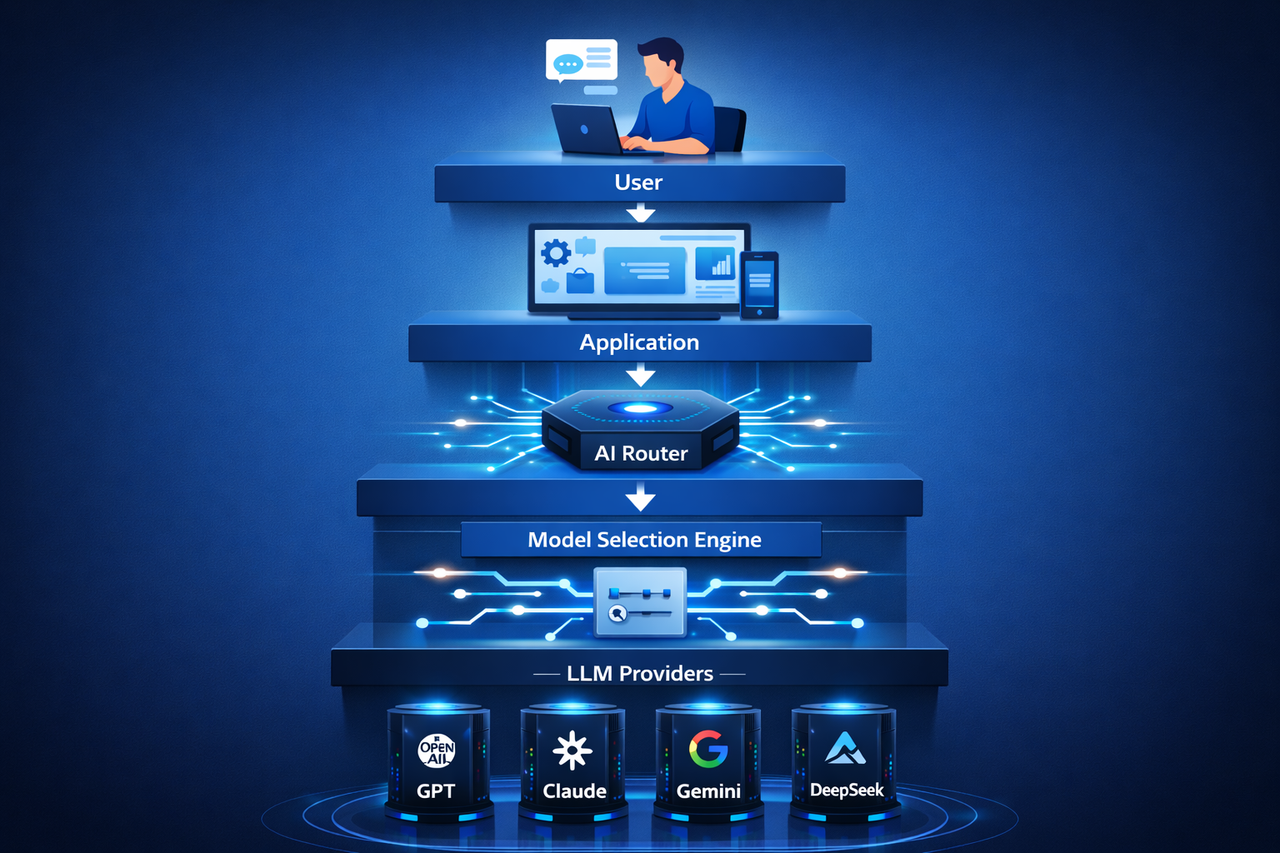
Lorsqu’un utilisateur ou un Agent IA soumet une requête, l’AI Router analyse la tâche, sélectionne le modèle optimal et renvoie les résultats à l’application.
Comparaison des stratégies de routage d’IA les plus courantes
Dans les infrastructures IA réelles, le routage de modèles combine plusieurs stratégies pour optimiser les performances.
Stratégie axée sur le coût : Privilégie les modèles économiques pour la majorité des tâches, réservant les modèles performants aux tâches complexes.
Stratégie axée sur la performance : Privilégie la qualité des résultats, en sélectionnant les modèles les plus performants, quel que soit le coût.
Stratégie hybride : Les AI Routers modernes adoptent souvent une approche hybride, équilibrant coût, performance et rapidité.
Stratégie spécifique à la tâche : Sélectionne des modèles optimisés pour des tâches précises, comme la génération de code ou le traitement multimodal.
Chaque stratégie convient à un type d’application IA différent ; les systèmes de routage doivent donc s’adapter aux besoins concrets.
Routage de modèles d’IA vs. Passerelle API IA
Le routage de modèles d’IA et la passerelle API traditionnelle remplissent des fonctions bien distinctes.
Passerelle API IA : Gère principalement les requêtes API — authentification, gestion du trafic, sécurité — mais ne sélectionne pas les modèles d’IA.
AI Model Router : Se concentre sur le choix du modèle d’IA le plus approprié pour chaque requête et assure son routage.
Les développeurs combinent souvent ces composants : la passerelle API gère la circulation des requêtes, l’AI Router gère la sélection des modèles.
Scénarios typiques d’utilisation du routage de modèles d’IA
Avec l’expansion de l’écosystème IA, le routage de modèles d’IA est massivement déployé dans de nombreux scénarios, permettant la coordination de modèles variés pour plus d’efficacité.
Agents IA : Les Agents IA ont souvent besoin d’accéder à différents modèles pour des tâches complexes comme la recherche d’informations, l’analyse ou la génération de contenu. Le routage de modèles permet aux agents de choisir automatiquement le modèle optimal.
Plateformes AI SaaS : De nombreuses plateformes SaaS proposent l’accès à plusieurs modèles, notamment divers grands modèles de langage. Les AI Routers facilitent la gestion des API de ces modèles.
Analyse de données IA : En analyse de données, différents modèles peuvent intervenir pour le parsing, le raisonnement logique ou la génération de résultats.
Architecture type d’une infrastructure AI Router
Un système AI Router performant s’appuie sur plusieurs couches :
Couche d’accès API : Reçoit les requêtes des applications ou des Agents IA.
Couche de décision de routage : Analyse le contenu des requêtes pour déterminer le modèle d’IA à utiliser.
Couche d’exécution des modèles : Se connecte à plusieurs fournisseurs de modèles, y compris différents services de grands modèles de langage.
Système de monitoring et d’optimisation : Suit les performances des modèles, les temps de réponse et les coûts d’invocation, afin d’optimiser en continu les stratégies de routage.
Cette architecture assure une répartition efficace des tâches entre les modèles et garantit une infrastructure IA flexible.
Le rôle de GateRouter dans l’écosystème AI Router
Avec la généralisation des applications IA multi-modèles, des plateformes AI Router spécialisées émergent pour aider les développeurs à gérer plusieurs modèles.
Certains fournisseurs d’infrastructure IA proposent désormais des interfaces unifiées d’accès aux modèles, comme la plateforme GateRouter, qui gère plusieurs services de grands modèles de langage.
GateRouter va au-delà des passerelles API traditionnelles en mettant l’accent sur les scénarios d’applications automatisées. Elle permet aux Agents IA d’accéder aux modèles, prend en charge l’invocation et l’exécution automatisées des tâches, et intègre le protocole x402 pour les paiements automatisés des agents — permettant aux machines de régler des paiements lors de l’utilisation de services.
Résumé
Le routage de modèles d’IA est une technologie centrale des architectures multi-modèles. En répartissant dynamiquement les tâches entre plusieurs modèles d’IA, les AI Routers permettent d’optimiser la performance, le coût et la rapidité de réponse des applications.
Avec l’essor des Agents IA et des applications automatisées, les architectures multi-modèles s’imposent comme une tendance majeure dans l’IA. Le routage de modèles d’IA améliore l’efficacité, la stabilité et la flexibilité.
Les plateformes AI Router deviennent ainsi des infrastructures incontournables reliant modèles d’IA, développeurs et applications automatisées.
FAQ
Qu’est-ce que le routage de modèles d’IA ?
Le routage de modèles d’IA est un mécanisme technologique qui sélectionne dynamiquement le modèle le plus adapté pour traiter des requêtes parmi plusieurs modèles d’IA.
Quelle est la différence entre AI Router et LLM Router ?
LLM Router désigne spécifiquement le routage pour les grands modèles de langage, tandis que AI Router englobe la gestion de différents types de modèles d’IA.
Pourquoi les applications d’IA ont-elles besoin d’architectures multi-modèles ?
Les modèles d’IA diffèrent en capacité, en coût et en rapidité. Les architectures multi-modèles permettent de sélectionner le modèle le mieux adapté à chaque tâche.
Comment le routage de modèles d’IA permet-il de réduire les coûts ?
Le routage oriente les tâches simples vers des modèles économiques, tandis que les tâches complexes sont confiées à des modèles performants, ce qui réduit les coûts d’exploitation globaux.








