Phénomène : Les récits autour des agents s’intensifient, mais l’efficacité opérationnelle ne suit pas
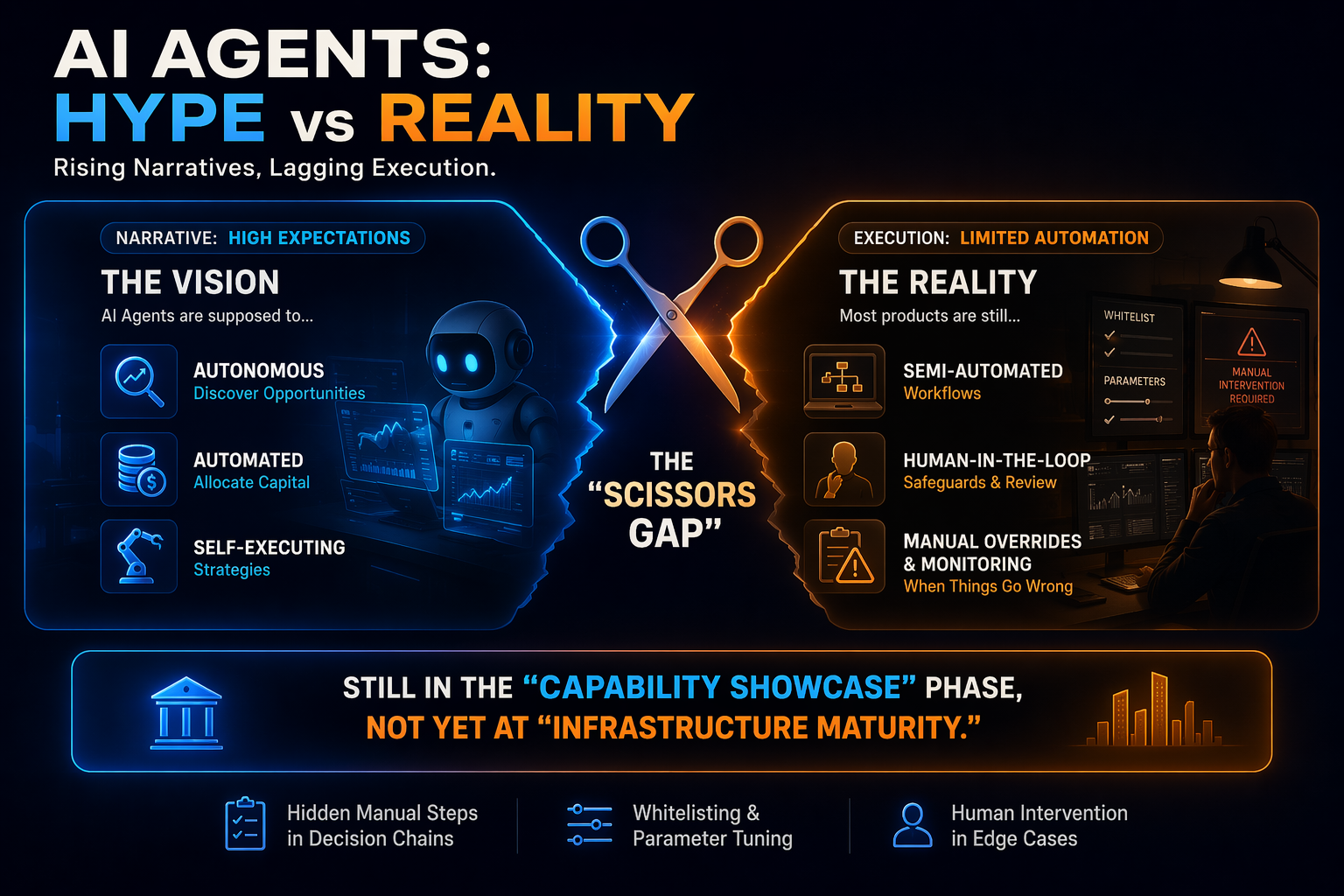
Le marché actuel montre un « écart en ciseaux » évident :
-
Sur le plan narratif, les agents devraient « découvrir automatiquement des opportunités, allouer automatiquement des fonds et exécuter automatiquement des stratégies ».
-
Sur le plan de l’exécution, la majorité des produits se limitent à des workflows semi-automatisés avec recours manuel.
Cela indique que l’industrie reste en « phase de démonstration de capacité » et n’a pas encore atteint la « phase de structuration de l’infrastructure ».
Beaucoup de produits affichent une automatisation, mais la prise de décision centrale repose encore sur des préjugements manuels — filtrage par liste blanche, gestion des paramètres de stratégie, intervention lors d’événements anormaux.
Idée reçue : Le problème central n’est pas la faiblesse du modèle, mais le manque de coordination systémique
On attribue souvent les difficultés d’implémentation à « un modèle pas assez intelligent ». Cela ne couvre qu’une partie du problème. La contrainte majeure est que, quelle que soit la puissance du modèle, il lui faut un système d’exploitation utilisable.
Pour qu’un agent on-chain accomplisse une tâche complète, il doit surmonter au moins quatre obstacles :
-
Identifier les cibles interactives ;
-
Confirmer leur authenticité et leur fiabilité ;
-
Comprendre leur signification économique ;
-
Exécuter sous contraintes de risque et vérifier les résultats.
Le vrai point faible aujourd’hui : l’infrastructure on-chain n’offre qu’un soutien limité pour les trois premières étapes. Autrement dit, le problème n’est pas « peut-il placer des ordres », mais « existe-t-il un système fiable de cognition et de contraintes en amont ».
Quatre frictions fondamentales : découverte, crédit, données, exécution
Friction de découverte : le monde ouvert est vaste, mais les opportunités pertinentes sont rares
Les réseaux sans permission permettent à chacun de déployer des contrats. Pour un agent, protocoles légitimes, contrats Testnet, forks malveillants et projets coquilles sont presque indiscernables en matière de découvrabilité. « Voir un contrat » ne signifie pas « voir une opportunité », et encore moins « voir une opportunité exécutable ».
Les systèmes quantitatifs traditionnels fonctionnent dans des ensembles fermés, car les frontières stratégiques sont prédéfinies.
Pour que les agents découvrent dynamiquement des opportunités à l’exécution, ils doivent assumer le coût supplémentaire du « jugement de pertinence » — c’est la friction de découverte.
Friction de crédit : les adresses on-chain sont vérifiables, l’identité économique ne l’est pas
Les blockchains vérifient signatures et changements d’état, mais ne valident pas « s’agit-il d’un déploiement officiel » ou « ce token est-il un actif standard du marché ». En pratique, le jugement de crédit s’appuie sur les interfaces, la documentation, la réputation sociale et le consensus écosystémique. Pour les humains, c’est basé sur l’expérience ; pour les agents, c’est un champ manquant.
Résultat : les agents font face à deux risques majeurs au niveau du crédit :
-
Interagir avec des adresses incorrectes, des tokens contrefaits ou des affiliés anormaux ;
-
Continuer à opérer sur la base d’hypothèses obsolètes après modification de la gouvernance ou des permissions.
Dans les systèmes de capitaux, ces erreurs ne sont pas anodines — elles génèrent des pertes directes.
Friction de données : avoir des données ne signifie pas disposer de données exploitables
Les données on-chain sont abondantes, mais la sémantique économique n’est pas standardisée. Même sur les marchés de prêt, chaque protocole peut avoir des structures d’interface, des champs d’état, des unités et des fréquences de mise à jour différentes.
Pour comparer entre protocoles, les agents doivent d’abord reconstruire la sémantique :
-
Quel champ représente la liquidité réellement disponible ;
-
Quel paramètre impacte le ratio de santé ;
-
Quel taux d’intérêt reflète le rendement réalisable, et non simplement l’affichage nominal.
Sans couche sémantique standardisée, les agents dépensent beaucoup de calcul et de temps en « assemblage de données », ce qui réduit la rapidité et la précision des décisions.
Friction d’exécution : une transaction réussie n’équivaut pas à la réalisation de la tâche
Une confusion fréquente consiste à assimiler « trader on-chain » à « objectif atteint ». En réalité, les tâches des agents sont souvent des processus multi-étapes :
Approbation -> Routage -> Échange -> Dépôt -> Rééquilibrage -> Contrôle du risque.
Tout slippage, retard, variation de liquidité ou dérive d’état peut entraîner un résultat final différent de l’objectif initial.
La couche d’exécution doit donc fournir « des contraintes stratégiques et une vérification post-exécution », pas seulement « la diffusion d’une transaction ».
Pourquoi la friction sera encore plus marquée en 2026
En 2026, les agents évoluent rapidement d’« outils d’information » à « exécutants de capitaux ».
Quand les permissions passent de « lecture » à « écriture », le risque passe de « répondre incorrectement » à « mal allouer des fonds ».
Trois tendances sectorielles amplifient ce problème :
-
Les environnements multi-chain et cross-chain deviennent plus complexes, avec une hétérogénéité d’interface croissante ;
-
L’innovation des protocoles s’accélère, mais la standardisation reste à la traîne ;
-
Les attentes du marché pour la commercialisation des agents augmentent, alors que la tolérance à l’erreur diminue.
Résultat : plus le récit s’intensifie, plus les faiblesses de l’infrastructure sont révélées.
Quels scénarios arriveront en premier, et lesquels resteront à haut risque
Scénarios les plus susceptibles d’être mis en œuvre en premier
-
Rééquilibrage de fonds au sein de protocoles sur liste blanche ;
-
Gestion de trésorerie sur une seule chaîne, quelques protocoles, et des trades peu fréquents ;
-
Tâches de paiement et de règlement automatisés avec des objectifs et des frontières clairement définis.
Ces scénarios présentent des limites environnementales claires, des espaces d’exception maîtrisables et des responsabilités bien définies.
Scénarios restant à haut risque
-
Arbitrage cross-chain à haute fréquence et découverte dynamique de protocoles inconnus ;
-
Allocation autonome sur l’ensemble du marché sans contrainte de liste blanche ;
-
Changement de stratégie entièrement automatisé dans des environnements à effet de levier élevé et faible liquidité.
Ces scénarios ne sont pas interdits à jamais, mais à ce stade, les « prérequis d’infrastructure fondamentale » ne sont pas encore réunis.
Une voie plus réaliste pour la mise en œuvre : contraindre d’abord, élargir ensuite
La voie la plus réaliste pour l’adoption des agents on-chain n’est pas l’autonomie totale immédiate, mais une approche progressive.
Étape 1 : couche d’objets de confiance
D’abord, traiter « avec qui interagir » :
-
Registres d’adresses standardisés ;
-
Preuves d’authenticité des tokens et protocoles ;
-
Surveillance en temps réel des contrats évolutifs et des changements de permissions.
Étape 2 : couche de données sémantiques
Ensuite, traiter « quoi comprendre » :
-
Modèles d’objets économiques unifiés entre protocoles ;
-
Paramètres de risque standardisés ;
-
Indexation et snapshots de données traçables et à faible latence.
Étape 3 : couche d’exécution contrainte
Puis, traiter « comment agir » :
-
Moteurs d’expression d’intention et de contraintes stratégiques ;
-
Orchestration d’exécution multi-étapes et rollbacks en cas d’échec ;
-
Simulation pré-trade et vérification post-trade des résultats.
Étape 4 : couche de responsabilité et de gouvernance
Enfin, traiter « que faire en cas d’incident » :
-
Gradation des permissions et mécanismes de coupe-circuit ;
-
Audit des opérations et attribution des responsabilités ;
-
Procédures de reprise collaborative humain-machine.
En construisant progressivement ces quatre couches, les agents passeront de la « démonstration » à la « délégation de confiance ».
Conclusion : la réussite des agents on-chain dépend d’une infrastructure d’exécution fiable
Les agents IA sont difficiles à implémenter on-chain non pas parce que les blockchains ne peuvent pas exécuter ou que les modèles ne peuvent pas raisonner, mais parce qu’il n’existe pas de couche d’intégration industrielle reliant les deux.
À ce stade, les critères d’évaluation les plus importants ne sont pas « jusqu’où les agents peuvent aller », mais :
-
Peuvent-ils éviter de perdre le contrôle en situation anormale ;
-
Peuvent-ils maintenir une interprétation cohérente dans des environnements multi-protocoles ;
-
Les résultats d’exécution peuvent-ils être reliés à des cibles vérifiables ;
-
La responsabilité du risque peut-elle être attribuée à un mécanisme gouvernable.
Le prochain enjeu compétitif passera de « qui raconte le meilleur récit d’agent » à « qui complète en premier la pile d’exécution fiable ».
Les plateformes qui permettent en premier des scénarios contraints et établissent des boucles fermées stables seront les mieux placées pour devenir des couches d’infrastructure à long terme. Les produits misant sur une haute autonomie sans contrôle du risque ni capacité sémantique robuste continueront à faire face à un double goulot d’étranglement en matière d’implémentation et de confiance.








